
[Spark] Apache Livy로 Spark 사용하기
Apache Livy
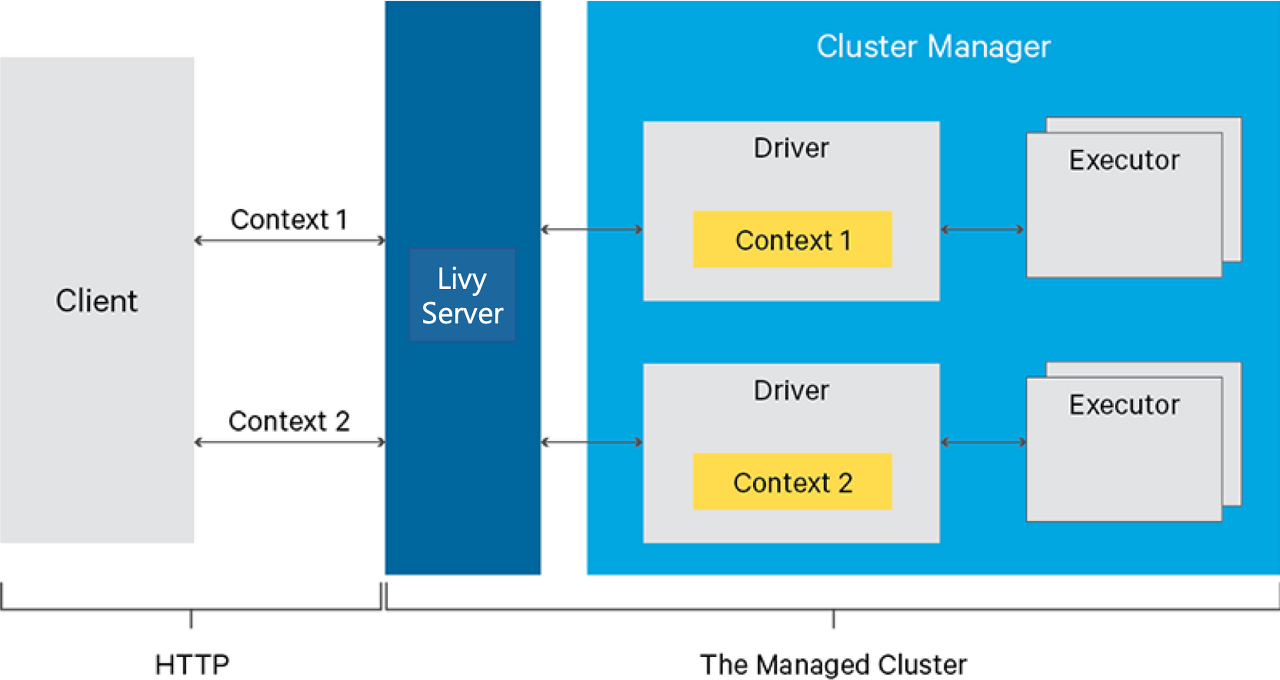
Apache Livy는 Apache Spark와 같은 대규모 분산 데이터 처리를 위한 오픈소스 클러스터 컴퓨팅 프레임워크로 이를 원격으로 실행할 수 있는 RESTful 웹 서비스를 제공한다.
Livy는 Spark와 함께 사용할 수 있는 클라이언트 프로그램에서 Spark 잡을 실행하고 관리하는 데 사용된다. 일반적으로 Spark와 함께 사용하는 언어 중 하나인 Python, Java, Scala, R에서 코드를 작성할 수 있고 이를 Livy REST API를 통해 서버에서 실행할 수 있다.
Livy는 클라이언트와 Spark 사이의 매개체 역할로 Spark 잡 실행을 위한 클러스터 리소스를 동적으로 할당하고 관리가 가능하다.
또한 대화형 분석, 스트리밍 분석, 배치 처리 등 다양한 Spark 애플리케이션 개발에 사용될 수 있다.
왜 Livy를 사용해야하는지?
Livy는 Spark 애플리케이션을 실행하고 모니터링하는 역할을 한다. Spark 애플리케이션을 클라이언트단에서 직접 실행하는 것이 아니라 Livy 서버에서 실행하고 애플리케이션 상태를 모니터링 할 수 있다.
Livy를 사용하면 클라이언트 애플리케이션은 Spark 애플리케이션을 직접 실행하지 않아도 되고 클라이언트의 리소스 부담이 적어진다.
또한 Livy는 클라이언트 애플리케이션이 Spark 클러스터에 직접 연결하지 않아도 되므로 보안과 관리면에서 용이하다. 클라이언트 애플리케이션은 Livy REST API를 사용해 Spark 애플리케이션을 실행하고 애플리케이션의 상태를 확인할 수 있으며 Livy 서버에서 돌린 애플리케이션의 출력을 쉽게 가져올 수 있다.
Livy를 통해 Spark Job 제출하기
import requests
import json
# Livy 서버의 주소
livy_url = "http://<livy_server_host>:<livy_server_port>/sessions"
# Livy REST API를 통해 Spark 세션 생성
data = {'kind': 'pyspark'}
headers = {'Content-Type': 'application/json'}
response = requests.post(livy_url, data=json.dumps(data), headers=headers)
session_url = response.json()['url']
session_id = response.json()['id']
# Spark job을 실행할 Livy 세션의 상태가 'idle'이 될 때까지 대기
while True:
response = requests.get(session_url, headers=headers)
status = response.json()['state']
if status == 'idle':
break
# Livy 세션에 Spark job을 제출
data = {'file': '/path/to/your/spark/job.py'}
headers = {'Content-Type': 'application/json'}
response = requests.post(session_url + '/jobs', data=json.dumps(data), headers=headers)
job_id = response.json()['id']
# Spark job이 완료될 때까지 대기
while True:
response = requests.get(session_url + '/jobs/' + str(job_id), headers=headers)
status = response.json()['state']
if status in ['success', 'dead', 'killed']:
break
# Livy 세션을 종료
requests.delete(session_url, headers=headers)
Leave a comment